

Specify the status
-
AvailableBusyAbsentNot defined


Этот плагин Вам очень пригодится, если Вы хотите сделать зависимость процента скидки от суммы заказа. Предположим, при заказе до 3000 рублей, клиент не получает скидки. При заказе от 3000 до 5000 рублей - скидка 3 %, и т.д.
Настройка плагина:
1. Покупаем и скачиваем плагин
2. Устанавливаем стандартным образом - через менеджер расширений
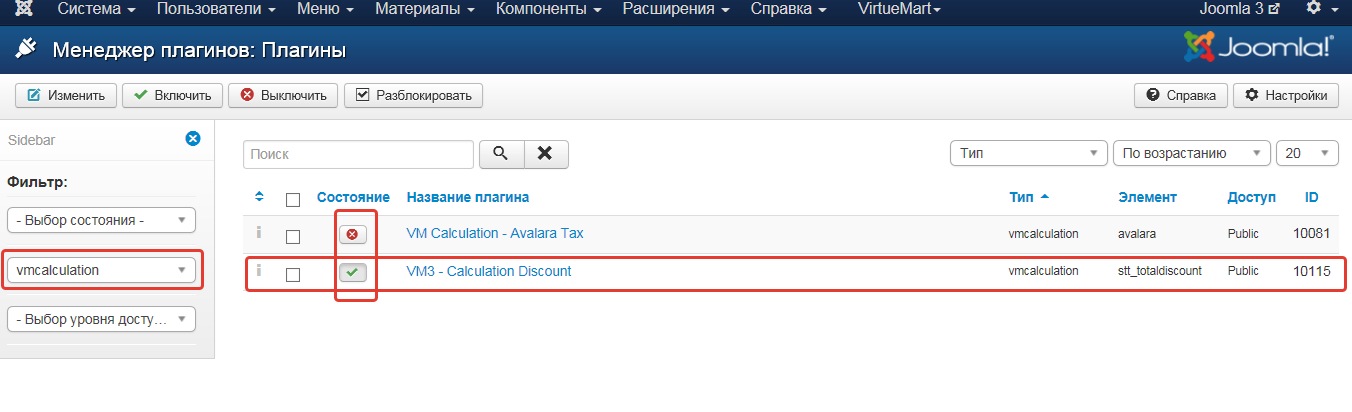
3. Заходим в менеджер плагинов и фильтруем по типу vmcalculation. Включаем плагин.
4. Заходим в VirtueMart-Налоги и правила расчета и создаем новую запись
5. Вводим название, Вид расчета - наценка, Операция - Скидка от суммы заказа. Сохраняем, иначе не появится блок настроек сумм и процентов. Далее есть два варианта настройки плагина. Либо указываем сумму и группу покупателей, либо сумму и процент скидки. В первом варианте цена товара соответствующая группе покупателей. Во втором варианте будет действовать процент скидки. Подробнее остановлюсь на виде расчета. Если Вы укажите "наценка", то скидка будет считаться на каждый товар отдельно. А если указать, например, "Цена после уплаты налогов за счет", то скидка будет считаться на всю сумму заказа.
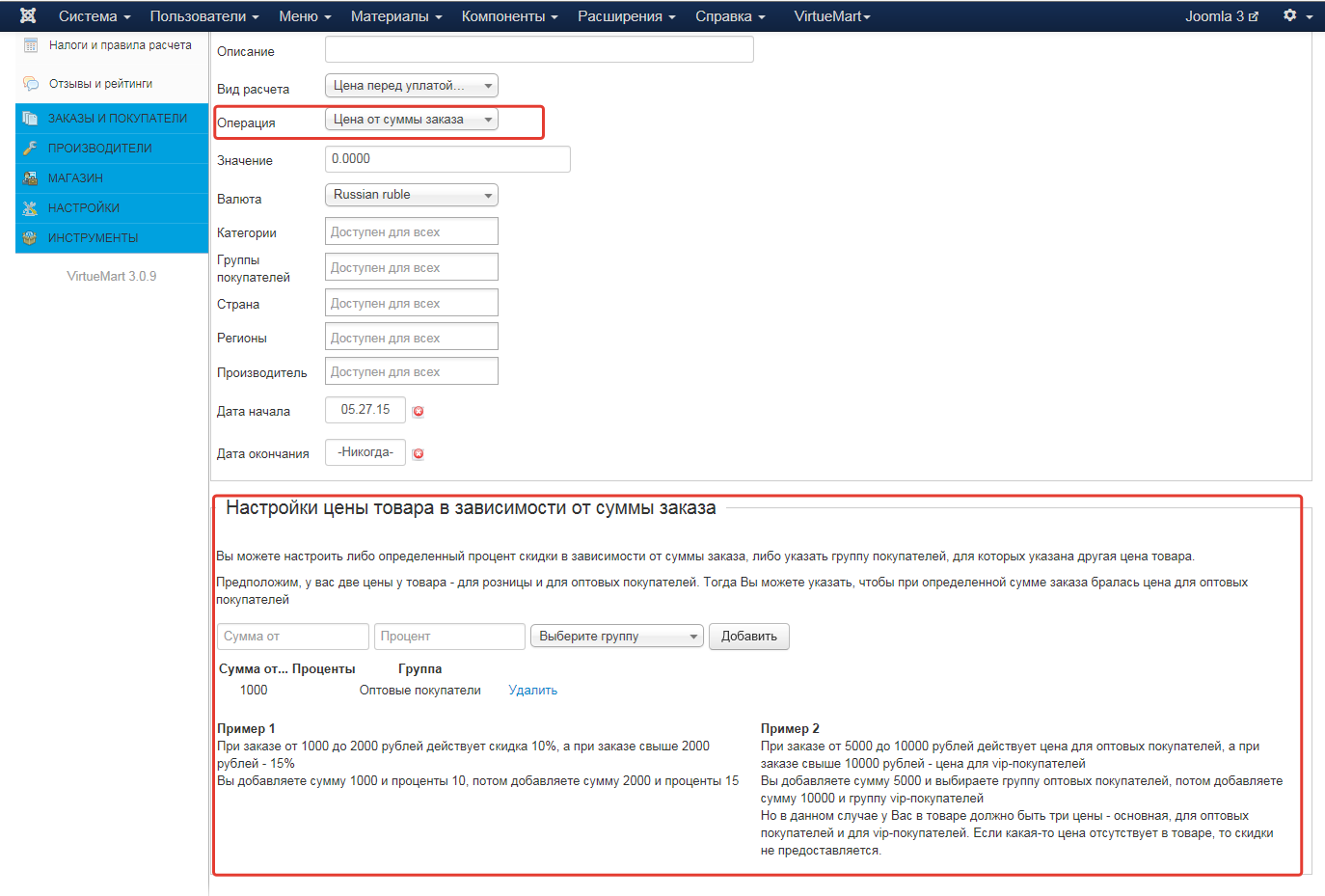
6. Публикуем, сохраняем, закрываем.
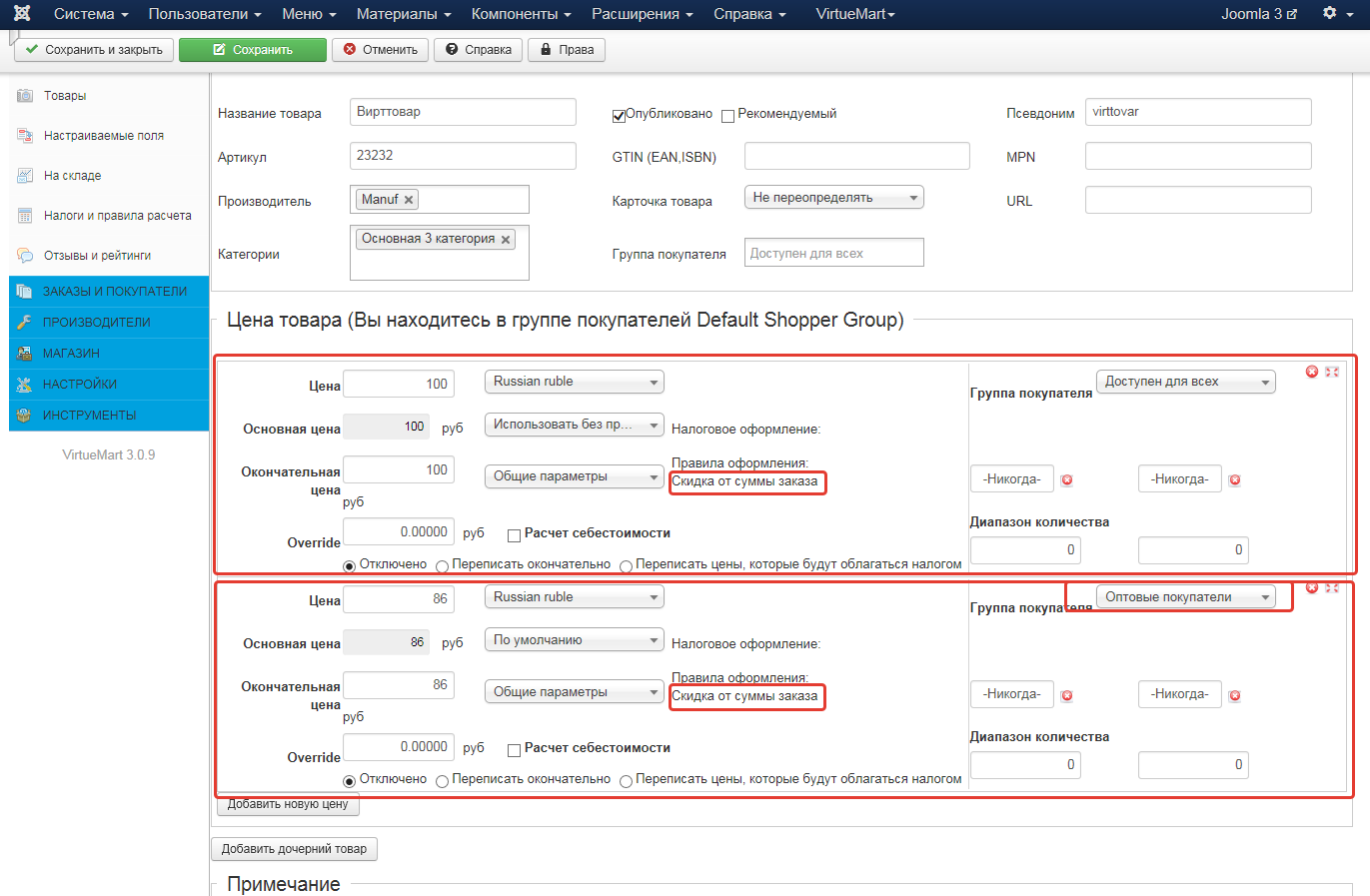
7. В настройках каждого товара проверяем, чтобы налоговое оформление стояло "по-умолчанию". Можно поставить конкретно "Скидка от суммы заказа". Для товаров, на которых нет скидки нужно выключить налоговое оформление. Если вы добавите несколько цен (для разных групп покупателя), то можно будет использовать эту группу для настройки плагина (см. пункт 5.)
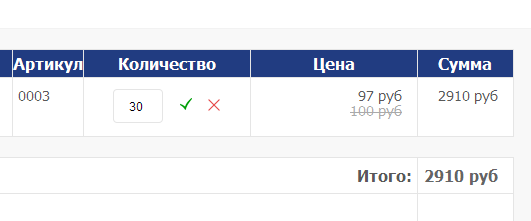
8. Кладем в корзину товаров на 3000 рублей, заходим в корзину и проверяем скидку.

Предиктивная модель - эффективный инструмент поддержки принятия бизнес-решений. Создание такой модели - процесс поиска закономерностей с использованием алгоритмов машинного обучения (Mashine Lerning) в существующем наборе исторических данных (обучение модели) для предсказания наиболее вероятных вариантов развития событий в будущем (применение модели).
Классифицирующая модель позволяет разбить большой массив данных на группы (классы), характеризующиеся сходным набором признаков, используя явные и неявные закономерности. Применение такой модели, позволяет, например, определить группы пользователей, характеризующихся определенным поведением и сделать им предложения, интересные именно для них.
Для обеспечения качества работы модели необходим тщательный отбор и подготовка входных данных. Также может возникнуть необходимость во внешних данных. Результатом моей работы будет:
1) сама модель в формате, определяемом выбранной моделью (например, в случае линейных моделей это будет вектор весов каждого из факторов. Вес фактора определяет степень его влияния на результат)
2) отчет о валидности (точности предсказания) модели
3) файл с результатами применения модели к исследуемому набору данных
